본 보고서는 총 2부로 구성되어 있다.
1부 : 롤토체스란 무엇인가?
이 장에서는 우리 프로젝트의 메커니즘과 도메인 지식을 이해할 수 있도록 간략한 설명을 덧붙였습니다.
1. 전략적 팀 전투(TFT)의 핵심 메커니즘과 데이터 복잡성
'전략적 팀 전투(Teamfight Tactics, 이하 TFT)'는 8명의 플레이어가 최후의 1인이 남을 때까지 무작위로 상점에 등장하는 기물(Unit)을 구매하여 자신만의 덱(Deck)을 구성하고 자동 전투를 벌이는 '오토 배틀러(Auto-battler)' 장르의 게임입니다.
플레이어는 한정된 자원(Gold)을 효율적으로 관리하며, 기물의 조합에 따라 발생하는 시너지(Trait)와 아이템(Item)을 최적화해야 합니다. 이는 게임 내 무작위성(RNG)을 수학적 확률과 통계적 전략으로 통제해야 함을 의미하며, 매 경기마다 생성되는 방대한 비선형 데이터는 머신러닝 모델의 예측 성능을 실험하기에 최적화된 환경을 제공합니다.
동일한 기물 3장을 모으면 해당 기물은 더 강력한 등급으로 진급하고, 이러한 방식은 최대 2번까지 이뤄질 수 있습니다.
2. 시즌 4 한정 메커니즘: '선택받은 자(Chosen)'
본 프로젝트의 대상이 되는 TFT 시즌 4는 '선택받은 자(Chosen)'라는 독특한 시스템을 도입하여 게임의 복잡성을 극대화했습니다. 상점에 등장하는 '선택받은 자' 기물은 구매 즉시 2성(2-Star)으로 강화된 상태이며, 특정 시너지를 두 개로 계산하는 강력한 특성을 지닙니다. 이러한 무작위성과 전략적 유연성의 결합은 플레이어의 덱 구성에 막대한 변동성을 부여하며, 결과적으로 머신러닝 모델이 학습해야 할 데이터의 차원과 잡음(Noise)을 크게 증가시킵니다.
2부 : 상용 통계 서비스의 역설계 : 머신러닝을 활용한 TFT 티어표 파이프라인 구축하기
- 목차
1. 프로젝트 동기
2. 데이터 선정 이유 및 데이터 소개
3. 문제 정의 및 전처리
4. 실험 결과
5. 결론 및 향후 계획
1. 프로젝트 동기 (Motivation)
전략적 팀 전투(TFT)와 같은 오토 배틀러 게임의 최상위 플레이어들은 'metatft'와 같은 통계 사이트에 의존해 현재 메타 덱과 순방(Top 4) 확률을 파악합니다. 이러한 사이트는 방대한 매치 데이터를 집계해 '어떤 덱이 강한가'를 직관적으로 보여주지만, 그 이면의 분석 과정은 사용자에게 철저히 블랙박스로 남아 있습니다. 본 프로젝트는 이 지점에서 출발합니다. 수업에서 학습한 머신러닝 기법을 통해 이 통계 사이트가 제공하는 인사이트를 직접 재현해보는 것이 목적입니다!
metatft 사이트 : https://www.metatft.com/
2. 데이터 선정 이유 및 출처
본 프로젝트는 Kaggle에 공개된 'TFT Fates Challenger EUW Rank Games' 데이터셋https://www.kaggle.com/datasets/mariuszmackowski/teamfight-tactics-fates-challenger-euw-rank-games을 활용합니다. 해당 데이터를 선정한 적정성 근거는 다음과 같습니다.
- 규모의 적정성: 약 10만 건의 매치 레코드를 포함하여 머신러닝 모델의 학습과 교차 검증에 통계적으로 충분하고도 넘칠 만큼의 표본을 제공합니다!
- 품질의 적정성: 하위 티어 데이터나 여러 시즌이 혼합된 데이터는 플레이의 무작위성이 크고 패치에 따른 메타 오염이 발생합니다. 반면, 본 데이터는 단일 시즌(Set 4), 단일 서버의 챌린저 티어(최상위 구간) 데이터만을 담고 있어 정석적인 메타가 뚜렷하게 드러나 분석의 신뢰도를 담보합니다.
- 형식의 적정성 및 도전 과제: CSV 기반의 정형 데이터 요구사항을 충족하면서도, 핵심 변수인 기물(units)과 시너지(traits)를 비롯해 식별자, 결과 및 성과, 경제 및 상태 지표 등등 데이터 분석에 매우 유용한 데이터부터 중요도가 낮은 데이터까지 모두 포함하고 있어, 수업시간에 배운 다양한 머신러닝 기법을 다방면으로 수행해보며 결과를 관찰해볼 수 있었습니다. 또한 '선택받은 자'라는 재미있는 데이터도 포함되어 있는데, 이 데이터에 대한 설명은 아래에서 계속합니다.
데이터는 총 14개의 변수로 구성되며, 분석 목적에 따라 다음과 같이 그룹화할 수 있습니다
- 식별자: match_id, puuid (전처리 단계에서 제거)
- 결과 및 성과 (Target 후보): placement (최종 순위), last_round, total_dmg_to_players, players_eliminated
- 경제 및 상태 지표: level, gold_left, time_in_game
- 덱 구성 (Feature 핵심, 반정형 데이터): units (기물, 아이템, 성급), traits (시너지)
- 선택받은 자 (Chosen) 시스템: chosen_unit, chosen_trait
특히 Set 4의 핵심 메커니즘인 '선택받은 자(Chosen)' 변수에는 약 12%의 결측치(NaN)가 존재합니다. 이는 단순한 수집 오류가 아니라, 플레이어가 전략적 판단에 따라 기물을 판매했거나 끝내 찾지 못한 '게임 내 상태' 그 자체를 의미합니다. 따라서 이를 삭제하지 않고 'None'이라는 독립적 범주로 대체하여 전처리를 수행할 계획입니다. 또한, 핵심 변수인 units와 traits는 아래와 같이 중첩 딕셔너리 형태의 문자열로 저장되어 있어, 이를 머신러닝 모델이 연산할 수 있는 특성 행렬로 변환하는 과정이 필수적입니다.
3. 문제 정의 및 전처리
본 프로젝트의 궁극적인 목표는 세 가지 별개의 Task를 수행하는 것을 넘어, 이를 '어떤 덱이 좋은 덱인가'라는 하나의 거대한 질문으로 관통시키는 것입니다. 이를 위해 다음과 같은 논리적 파이프라인을 구축합니다.
- 클러스터링 (비지도 학습): units와 traits 변수만을 입력하여 현재 챌린저 메타를 주도하는 덱 아키타입(후보군)을 수학적 군집으로 도출합니다.
- 분류 (지도 학습): 도출된 각 덱이 순방(Top 4)에 성공할 것인지를 이진 분류하여 덱의 '안정성'을 판정합니다. Target은 placement(최종 순위) <= 4 여부로 설정합니다.
- 회귀 (지도 학습): 각 덱이 가하는 평균 데미지 계산식 : (total_dmg_to_players) / last_round 를 Target으로 삼아 덱의 절대적인 '화력' 파워를 수치화합니다.
- 통합 해석: 위 결과를 종합하여 X축(안정성)과 Y축(화력)으로 구성된 나만의 2축 사분면 티어표를 완성합니다.

여기서 분류와 회귀의 Target을 분리(순위 vs 데미지)한 것은 논리적 오류를 방지하기 위함입니다.
회귀 Target을 분류와 동일하게 순위로 설정할 경우 두 Task가 동어반복이 되지만, 데미지로 분리함으로써 '안정성'과 '화력'이라는 독립적인 분석 축을 확보할 수 있습니다.
본 프로젝트는 다음과 같은 창의성과 차별점을 갖추며 높은 완성도와 논리적 완결성을 갖추도록 노력했습니다. 첫째, 상용 메타 분석 서비스가 블랙박스로 제공하는 통계를 수집된 데이터와 머신러닝을 통해 직접 리버스 엔지니어링(역설계)합니다. 둘째, 로지스틱 회귀의 가중치(Weight)와 랜덤 포레스트의 특성 중요도(Feature Importance) 등 머신러닝이 가진 '해석 가능성'을 무기로 삼아, '왜 이 덱이 강한가'를 데이터 기반으로 설명합니다. 셋째, 수업시간에 배운 교과서적인 내용에 추가해, 교수님이 수업시간에 언급하신 여러 다양한 통찰들을 추가적으로 담아 더 완성도 높은 보고서를 만드려 노력했습니다.
3 - 1. 프로젝트의 청사진
1.1 분석 목표
본 프로젝트는 TFT(전략적 팀 전투) 시즌 4 EUW 챌린저 매치 데이터를 바탕으로, 메타를 주도한 핵심 덱 구성을 발굴하고 그 성과를 정량 평가하는 것을 목표로 한다. 단일 패치(10.25) 데이터로 한정해 메타의 일관성을 확보했으며, 패치마다 메타가 달라 여러 패치를 섞으면 티어 분석 자체가 무의미해지기 때문이다. 전처리·EDA·클러스터링·분류·회귀·통합 해석의 6단계는 각각 독립된 과제가 아니라, "어떤 덱이 좋은 덱인가"라는 하나의 질문을 향해 클러스터링(어떤 덱이 있는가)·분류(순방하는가)·회귀(얼마나 센가)·통합(그래서 티어가 무엇인가)으로 수렴하도록 설계했다.
1.2 0단계 — 전처리
문자열로 저장된 기물(units)·시너지(traits) 데이터를 ast.literal_eval로 안전하게 파싱해 정형 특성 행렬로 변환한다. 기물은 존재 여부가 아닌 성급(1~3성)을 순서형 변수로 매핑해 강화 정도를 모델이 학습하도록 했고, chosen_unit·chosen_trait의 결측(12%)은 삭제 대신 SimpleImputer로 'None' 범주로 대체해 "선택받은 자를 얻지 못한 상태" 자체를 의미 있는 정보로 보존했다. 등장 빈도가 낮은 비주류 기물·시너지는 'Others' 열로 병합해 차원을 물리적으로 축소했다. 수치형 변수는 표준화(StandardScaler)·정규화(MinMaxScaler) 두 벌을 모두 생성해 비교하되, 최종 채택은 표준화로 한다 — 골드·데미지·생존시간에 극단적 이상치가 존재해 MinMax는 정상 데이터가 좁은 구간에 압축되는 문제가 있기 때문이다. 원-핫 인코딩 시 drop_first=True는 다중공선성 일반이 아니라 더미 변수 간의 완전공선성(더미 변수 함정)만을 제거하는 장치임을 명시하며, 기물 간의 구조적 동반 출현으로 인한 다중공선성은 별개의 문제로 4단계 규제 회귀에서 다룬다.
1.3 1단계 — 탐색적 데이터 분석(EDA)
모델링 이전에 데이터를 직접 이해하고, 이후 모든 단계의 feature 선정 기준을 확정하는 관문 단계다. 분류 타깃은 순방 여부(is_top4, placement 1~4등)로 정의했으며, 정확히 50:50의 클래스 비율을 통해 8인 로비 단위 데이터 수집의 무결성을 검증했다. 회귀 타깃은 당초 검토했던 total_dmg_to_players 단독이 아니라, 생존 시간으로 정규화한 분당 데미지(dmg_per_min = total_dmg_to_players / (time_in_game/60))로 최종 확정했다. 이는 생존이 길수록 누적 데미지가 커지는 교란을 제거해 "순수 화력"을 측정하기 위함이며, 왜도·첨도가 정규분포에 근접해 별도의 타깃 변환이 불필요함도 함께 확인했다. 상관관계 히트맵 분석 결과 placement·time_in_game·total_dmg_to_players가 덱의 강함이 아니라 "오래 살아남았다는 결과"를 반영하는 사후정보임을 확인하고, 이 세 변수를 누수(leakage) 블랙리스트로 격리했다. 한편 level은 당초 사후정보 후보로 검토했으나, 회색지대 판단의 모호성을 피하기 위해 최종적으로는 누수 논쟁 없이 정상 도메인 피처로 유지하기로 했다 — 빠른 레벨링이 보드 강함의 원인이라는 해석이 가능하기 때문이다. 이후 3단계 분류 과정에서 last_round(생존 길이)·players_eliminated(게임 진행도) 역시 순방 여부와 직결되는 사후정보임이 드러나 블랙리스트에 추가했으며, 최종 블랙리스트는 placement, time_in_game, total_dmg_to_players, last_round, players_eliminated 다섯 변수로 확정했다. 손상 로비로 판단되는 level 1 구간(표본 32개, 평균 데미지 0)은 EDA 단계부터 분석에서 제외했다. 마지막으로 특성 선택 단계에서는 L1 규제(Lasso)에 의한 자동 선별과, 덱 평균 성급·활성 시너지 개수 등 파생 변수 생성 두 접근을 비교해, 10만 단위 데이터에서는 SBS류의 순차 탐색보다 L1 규제가 연산 효율 면에서 더 적합함을 실증했다.
1.4 2단계 — 클러스터링(메타덱 발굴)
정답 레이블 없이 기물·시너지 구성만으로 메타를 주도한 덱 아키타입을 군집화한다. PCA는 1단계 EDA(사람이 이해하기 위한 원본 차원 분석)와 목적이 달라 — KMeans의 거리 계산이 잘 작동하도록 차원을 압축하는 역할로, 분류·회귀 단계에서는 해석 가능성을 위해 사용하지 않는다. 누적 분산 설명 비율 85% 기준으로 주성분 개수를 정당화했다. KMeans++로 k=2~15 구간에서 엘보우(SSE)와 실루엣 계수를 동시 그려 k=8을 채택했으며, 이때 탐색에 사용한 입력 공간(PCA 축소 데이터)과 최종 학습의 입력 공간을 PCA 데이터로 통일했다 — 탐색과 학습의 공간이 다르면 "실루엣 기준 최적"이라는 근거 자체가 최종 모델에 적용되지 않는 모순이 생기기 때문이다. 이 KMeans 라벨이 이후 3·4·5단계 전체로 전달되는 메인 덱 라벨이 된다. DBSCAN과 계층적 군집(Ward 연결)은 보조 분석으로 위치를 명확히 했다. 당초 DBSCAN의 노이즈를 "실패한 덱"으로 간주해 순도 높은 1티어만 걸러내려 했으나, 이는 부정확한 해석이다 — DBSCAN의 노이즈(-1)는 단지 파라미터 설정에 따른 저밀도 영역의 점일 뿐 덱의 강함과 무관하며, 군집 자체가 units/traits만으로 형성되므로 순방 여부와는 독립적이다. 어떤 덱이 1티어인가는 DBSCAN이 아니라 3·4단계에서 사후적으로 판정하며, DBSCAN은 어떤 메타덱이 조밀하게 뭉친 "정형 덱"이고 어떤 게 분산된 "변형 덱(pivot deck)"인지를 밀도로 보여주는 KMeans의 보조 진단으로 재정의했다. 이 역할 분리(밀도 ≠ 성과)를 시각적으로도 드러내기 위해, KMeans·DBSCAN 양쪽에 PC1·PC2 평면 산점도를 추가하고 DBSCAN의 저밀도 포인트는 회색으로 별도 표시했다.
1.5 3단계 — 분류(순방 예측)
각 덱 구성이 순방(top4)하는지를 이진 분류하며, 동시에 2단계 클러스터링 결과를 교차검증하는 역할도 겸한다. Perceptron부터 Logistic Regression, SGDClassifier 기반 Linear SVM 근사, Decision Tree, Random Forest, AdaBoost, GBM까지 선형에서 앙상블로 이어지는 모델 스펙트럼을 구성했다. 보고서의 핵심은 누수 제거 전후 성능 대조다 — 1단계에서 확정한 블랙리스트(다섯 변수)를 포함한 환경과 제거한 환경에서 각각 5-Fold 계층 교차검증을 수행해, "거짓 고성능"에서 "정직한 성능"으로의 하락폭을 정량적으로 제시한다. 튜닝은 GridSearchCV 대신 연산 효율이 더 높은 RandomizedSearchCV로 수행하며, make_pipeline으로 스케일러와 모델을 캡슐화해 폴드 내부의 정보 누수를 차단한다. 검증 전략은 중첩 교차검증 대신 holdout(80:20)을 채택했는데, 10만 건 이상의 대규모 데이터에서는 대수의 법칙에 따라 holdout만으로도 테스트셋이 충분한 모수를 확보해 통계적 신뢰성이 담보되며, 중첩 CV는 이 데이터 규모에서 연산 비용 대비 오차 감소 효과가 불균형하다는 학술적 근거로 정당화한다. 로지스틱 회귀의 L1·L2 규제를 비교해 순방 예측이 소수 핵심 기물에 의존하는지, 덱 전반의 균형에 의존하는지를 진단하고, 정밀도·재현율의 트레이드오프를 F1-Score로 종합 평가하며 ROC-AUC로 임계값 독립적 변별력을 검증한다. 마지막으로 단일 Decision Tree의 과적합을 Random Forest가 완화하는 과정을 Train-Test 갭으로 입증하고, 부스팅 계열(AdaBoost·GBM)은 이론적 전제인 약한 학습기(스텀프, max_depth=1)로 통제한 공정 조건에서 배깅과 비교한다. 또한 Random Forest의 특성 중요도를 1단계에서 세운 도메인 가설과 대조해 모델이 실제로 덱 구성을 학습했는지 검증한다.
1.6 4단계 — 회귀(덱 화력 스케일링)
분류가 순방/실패의 이진 판정이라면, 회귀는 그 안에서 연속적인 강도를 측정해 덱의 절대적 파워를 수치화한다. 회귀 타깃은 두 차례 조정을 거쳤다. 최초 검토안인 placement는 분류 타깃과 사실상 동일한 질문이 되어 세 task가 따로 노는 문제가 있었고, 이를 피하기 위해 total_dmg_to_players로 변경했으나 이는 생존 시간과 강하게 상관되어 "오래 살수록 누적 데미지가 큰" 생존 교란이 타깃에 그대로 남는 한계가 있었다. 최종적으로 dmg_per_min(분당 데미지)으로 시간 정규화해, 생존 길이와 독립적인 순수 화력 지표로 확정했다. 다만 이 정규화로도 생존-화력 간 상관(약 0.71)이 완전히 제거되지는 않는다는 한계를 인지하고 있으며, 5단계 통합 해석에서 두 축의 독립성을 재차 점검한다. 피처는 누수 차단을 위해 게임 진행 상태(level, gold_left)와 결과(placement)를 모두 제외하고 덱 구성(unit_/trait_) 변수만으로 한정했다 — 이는 단순 누수 회피가 아니라, 회귀의 목적 자체가 "덱 고유의 화력"을 게임 진행 상태와 분리해 측정하는 데 있고, 5단계에서 덱(클러스터) 단위로 화력을 집계하는 것과 정합하기 위함이다. OLS 베이스라인에서 다중공선성 문제를 제기하되, 이는 더미 변수 함정과는 별개로 특정 기물·시너지가 늘 함께 채용되는 구조적 동반 출현에서 비롯됨을 명시한다. Ridge(L2)·Lasso(L1)·ElasticNet을 교차검증으로 비교해 회귀에서의 정식 L1 vs L2 통찰을 완성하고, 화력이 소수의 사기 기물에서 나오는지 덱 전반의 균형에서 나오는지를 진단한다. RANSAC으로 게임 외적 노이즈(이상치)를 배제한 강건 회귀를 수행하고, 다항 회귀는 연속형 수치 변수에 한정해 교차항을 적용함으로써(이진 특성인 기물·시너지에는 적용하지 않음) 차원 폭발을 방지하며, Random Forest 회귀를 비선형 베이스라인으로 병행한다. 모든 모델의 잔차도와 R²·MSE를 종합 비교해 최종 모델을 선정하고, 이를 5단계의 화력 축 산출에 사용한다.
1.7 5단계 — 통합 해석
2단계가 분리한 메타덱 각각에 대해, 3단계 분류 모델이 예측한 순방 확률(안정성 축)과 4단계 회귀 모델이 예측한 화력(화력 축)을 좌표로 매겨 2축 산점도를 구성한다. 고화력·고순방은 정석 1티어(S), 저화력·고순방은 안정형(A), 고화력·저순방은 도박형(B, 한방 덱), 저화력·저순방은 비주류·함정 덱(C)으로 사분면을 정의한다. 클러스터링이 "어떤 덱이 있는가", 분류가 "그 덱이 순방하는가", 회귀가 "그 덱이 얼마나 센가"를 각각 답하고, 통합 해석이 이를 "그래서 티어가 무엇인가"로 종합함으로써 metatft식 티어표가 완성되며, 이는 세 task가 하나의 결론으로 수렴하는 프로젝트의 최종 목적지가 된다.
4. 구현 결과
1. 데이터 전처리 + 분석하기
0. 데이터 전처리 하기 : 코드 참조
1.1 타깃 변수 분포 및 정제 (도메인 지식 결합)
- 분류 타깃(is_top4)의 완벽한 클래스 균형을 확인하였으며, 이론상 순방이 불가능한 level <= 4 데이터(32건)를 '손상된 로비(AFK)' 통계적 노이즈로 규정하여 선제 제거함.
- 생존 시간 교란을 통제한 회귀 타깃($dmg\_per\_min$)의 왜도와 초과첨도를 산출하여, 향후 선형 규제 모델에서 잔차 정규성 진단을 위한 수학적 기준점으로 확립함.
1.2 데이터 누수(Data Leakage) 식별 및 차단
- 상관관계 히트맵 분석 결과, 타깃 변수 산출에 직접 개입하거나 매치 종료 시점에만 확정되는 placement, time\_in\_game, total_dmg_to_players를 '결과론적 지표'로 명확히 식별함.
- 예측 모델이 정답을 유추하는 구조적 치트키(누수)를 방지하기 위해, 이를 블랙리스트 변수로 지정하고 피처 공간에서 완전 격리 조치함.
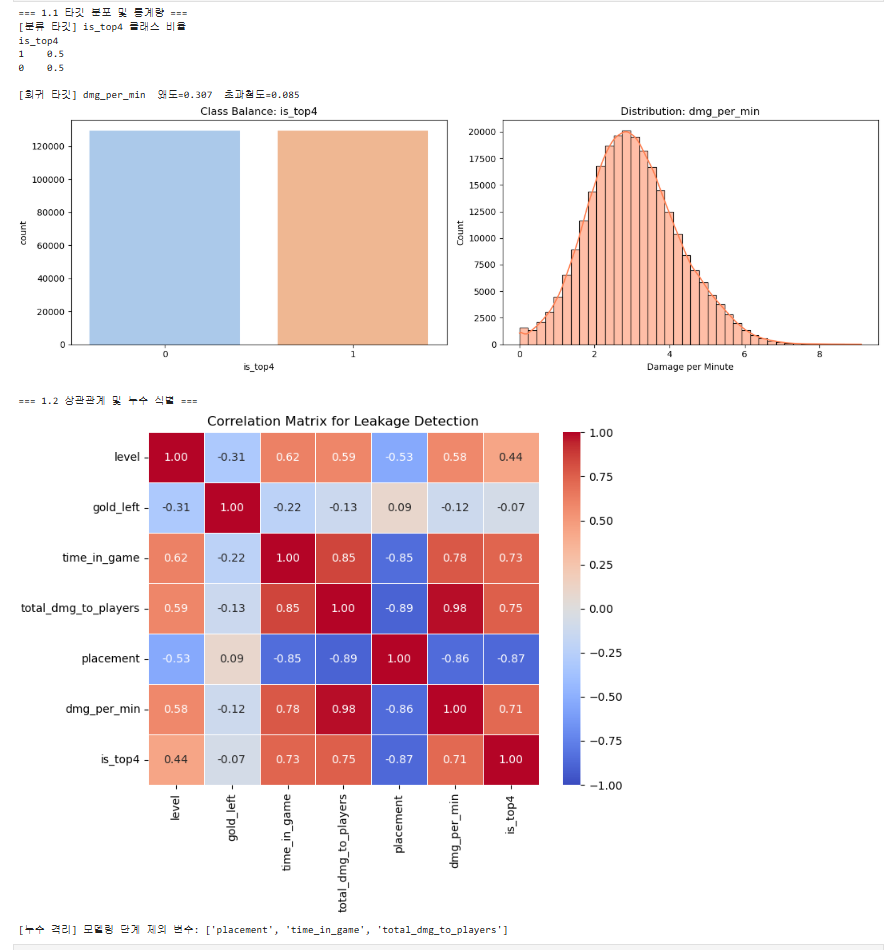
1.3 비선형성 증명 및 다중공선성(VIF) 통제
- 상수항을 포함한 중심화 $VIF$ 진단 결과, 유입되는 수치형 변수($level$, $gold\_left$) 간의 다중공선성 위험은 완벽히 통제됨을 입증함.
- 단, $gold\_left$와 $dmg\_per\_min$ 간의 관계를 LOWESS 추세선으로 시각화한 결과 극단적인 비선형성이 확인됨. 이는 선형 베이스라인 모델의 한계를 시사하며, 3단원의 비선형 트리 앙상블(Random Forest) 및 4단원의 다항 회귀(Polynomial Regression)를 주력으로 도입해야 할 압도적인 수학적 당위성을 제공함.
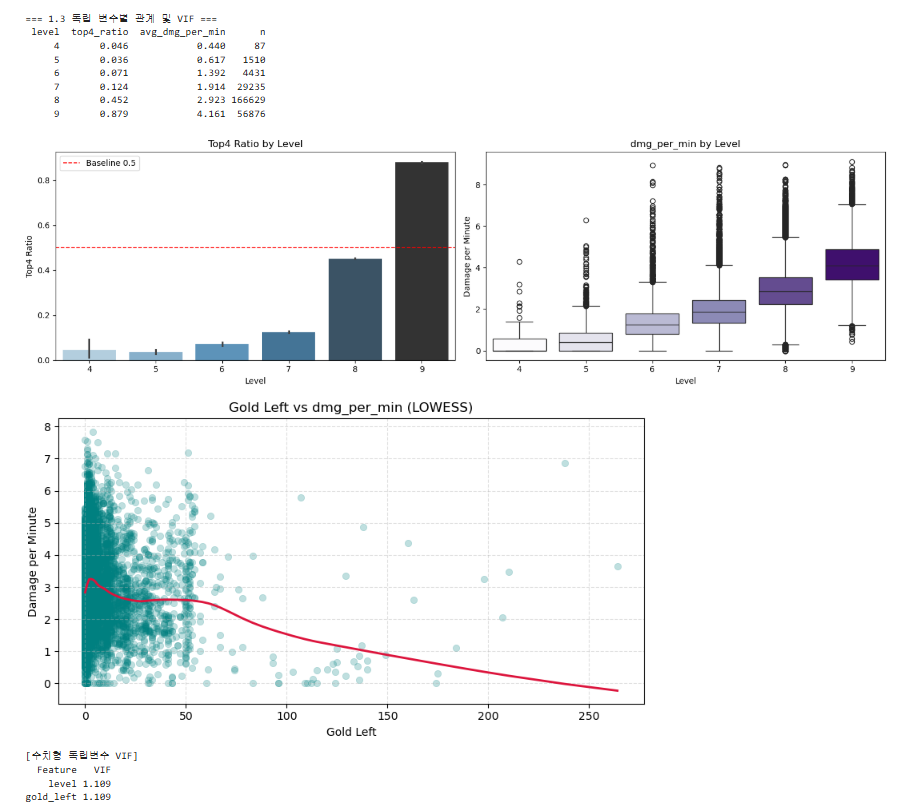
2. Task 1 : 클러스터링 (비지도 학습) - units와 traits 변수만을 입력하여 현재 챌린저 메타를 주도하는 덱 아키타입(후보군)을 수학적 군집으로 도출합니다.
2.1 차원 축소(PCA)
예측 변수와 완전히 분리된 기물/시너지 특성(비지도 학습 공간)에 한정하여 PCA를 적용, 원본 분산의 $85%$를 보존하면서도 차원의 저주와 희소성($Sparsity$) 노이즈를 성공적으로 압축함.

2.2 KMeans++ 기반 주류 메타 덱 규명 ($k=8$)
- 엘보우 기법의 완만한 하락세와 실루엣 스코어의 부분적 피크를 통해, 정형화된 메타 덱뿐만 아니라 덱 스왑(Pivot) 중간 단계의 변형 덱들이 연속적으로 혼재하는 게임 데이터의 도메인 특성을 확인.
- 실루엣 및 도메인 지식을 종합하여 $k=8$로 K-Means++ 모델을 학습시켰으며, 도출된 8개의 군집 중심 프로파일링(핵심 기물 및 시너지 추출)을 통해 5단계 통합 해석의 기준이 될 '메타 덱 행(Row)'을 성공적으로 확립함.
- 여러가지 메타 덱을 관찰할 수 있음!

2.3 상호 보완적 비선형/계층적 군집 진단
- 밀도 기반 DBSCAN을 통해 전체 공간의 상당 부분이 엄격한 정형 덱(조밀 군집)을 벗어난 '저밀도 변형 덱' 영역임을 입증함.
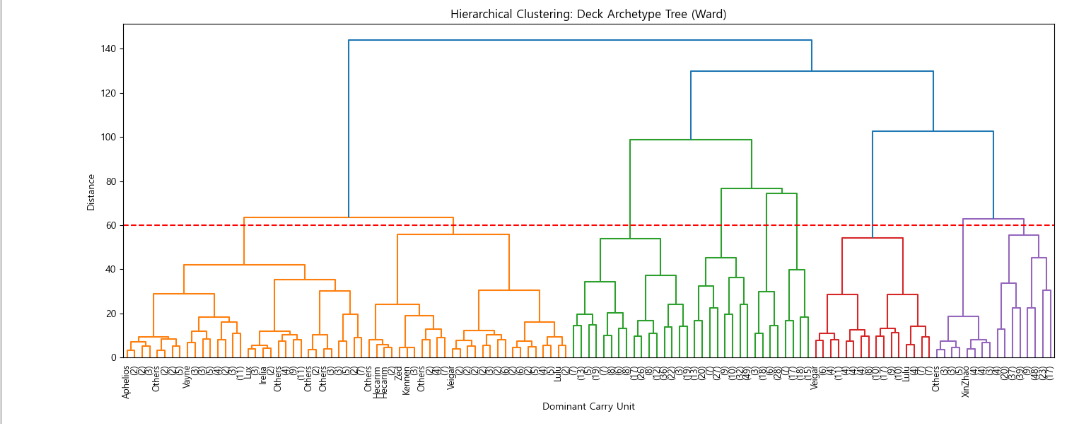
- 이는 K-Means의 기하학적 분할이 완벽하지 않더라도 덱의 뼈대(아키타입)를 파악하는 데는 유효함을 역으로 증명하며, 워드 연결법(Ward Linkage) 기반의 덴드로그램을 통해 핵심 캐리 기물 간의 계통적 진화 트리를 시각화함.
- 더욱 많은 수의 메타 덱(약 26개)를 관찰할 수 있었음! 그룹 수가 크게 묶인 메타덱과 작게 묶인 메타덱들이 있었는데, 작게 묶인 메타덱들은 여러 아류작들로 변형이 가능한 메타 덱들이 여러가지 변형을 하면서 각각 다르게 묶인 것들로 볼 수 있었음. 매우 흥미로운 결과였음! 또한 덴드로이드를 통해 핵심 기물, 핵심 특성이 무엇인 지도 관찰 할 수 있었음.

3. Task 2 : 분류 (지도 학습) - 도출된 각 덱이 순방(Top 4)에 성공할 것인지를 이진 분류하여 덱의 '안정성'을 판정합니다. Target은 placement(최종 순위) <= 4 여부로 설정합니다.
3.1 & 3.2 모델 스펙트럼 및 Data Leakage 통제
- 실험 목적: placement 타깃과 직결되는 사후 지표(레벨, 생존 시간, 딜량) 포함 여부에 따른 모델 성능 비교.
- 결과: 누수 변수 포함 시(환경 A) 모든 모델이 85% 이상의 비정상적 고성능을 보였으나, 제거 후(환경 B) 70% 초반으로 회귀함.
- 해석: 사후정보(last_round·players_eliminated·생존시간·누적딜)를 제거하자 RF 기준 0.912 → 0.798로 11.38%p 하락하여, 기존 고성능이 "오래 살아남았다는 결과"에 기댄 거짓임을 정량 입증했다. 제거 후엔 Logistic Reg(0.809)가 최상위로, 순수 덱 신호는 복잡한 앙상블보다 선형 분리에 가깝다는 의외의 사실이 드러났다.

3.3~3.4 튜닝 & 평가 — [결과: L1/L2 출력 + 4분할 대시보드]
10만+ 데이터라 중첩 CV 대신 Holdout(80:20)을 채택하고, F1을 주력 지표로 RF를 RandomizedSearch 튜닝했다(CV F1 0.805). L1·L2 활성 특성이 158/158로 동일해, 이진 기물 피처 특성상 규제 방식의 차이가 미미함을 과포장 없이 그대로 보고한다. 정밀도·재현율·F1이 모두 0.81, ROC-AUC 0.894로 무작위(0.5)를 크게 상회하여 누수 없이도 유의미한 변별력을 확보했으며, 검증곡선상 깊이 증가 시 train만 오르고 CV가 정체하는 과적합 구간을 포착했다.

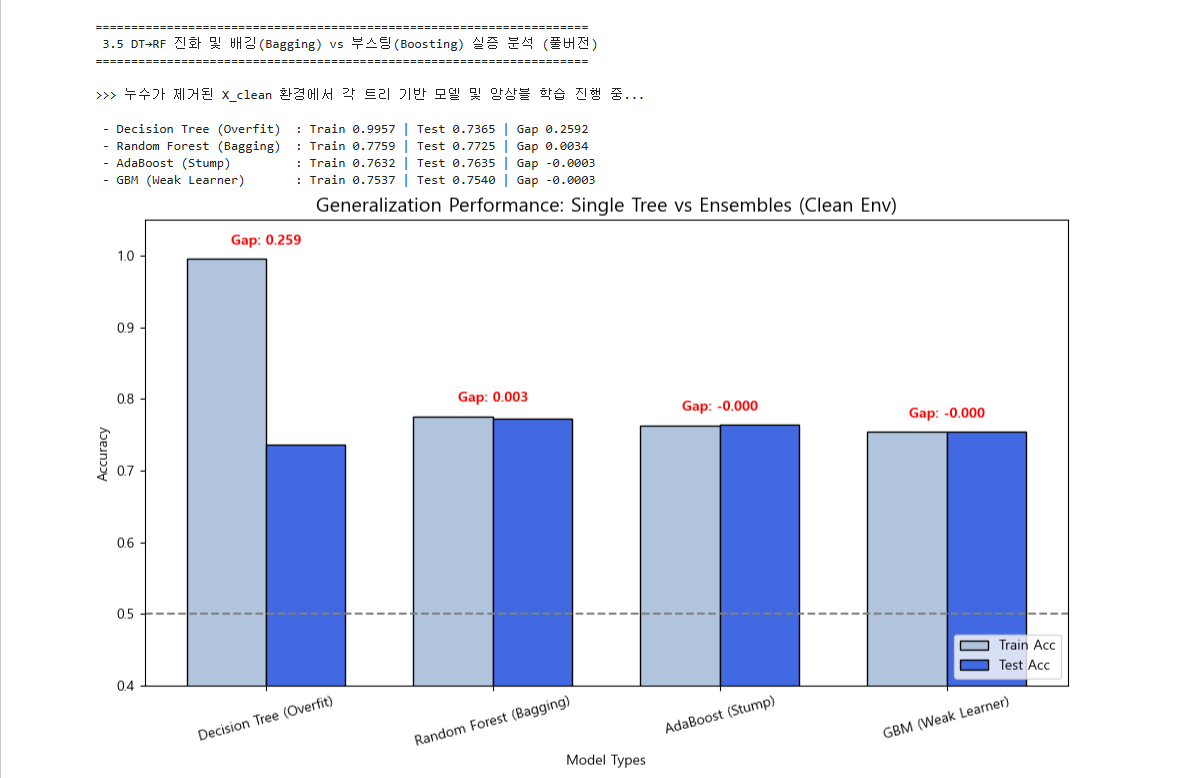
3.5 배깅 vs 부스팅 & 특성 중요도 — [결과: 일반화 막대 + 특성 중요도]
단일 DT는 Gap 0.259의 극심한 과적합을 보였고, RF가 Gap 0.003으로 분산을 거의 제거해 DT→RF 진화를 입증했다. 부스팅의 이론적 전제인 '약한 학습기'를 지키기 위해 AdaBoost·GBM을 max_depth=1 스텀프로 통제하자 두 모델의 과적합 Gap도 0 수준으로 정상화됐다. 통상 부스팅이 더 강력하다고 알려진 것과 달리, 동일하게 통제한 비교에서 테스트 정확도는 RF(0.773) > AdaBoost(0.764) > GBM(0.754)로 배깅이 우위였다. 이는 상점 RNG·탈주 등 설명 불가능한 노이즈가 큰 TFT 데이터에서, 오답에 가중치를 키우는 부스팅보다 다수결로 노이즈를 상쇄하는 배깅이 더 강건함을 시사한다. 누수를 걷어낸 뒤 특성 중요도 최상위에 level과 핵심 기물(Yone·Azir·Zilean)이 등장해 모델이 생존 결과가 아닌 덱 구성을 학습함을 확인했으며, level은 빠른 레벨링이 곧 보드 강함으로 이어지는 정상 도메인 신호로 해석한다.

4. Task 3 : 회귀 (지도 학습) - 각 덱이 가하는 평균 데미지 계산식 : (total_dmg_to_players) / last_round 를 Target으로 삼아 덱의 절대적인 '화력' 파워를 수치화합니다.
4.1~4.2 : 계수 분포 + Lasso top 10
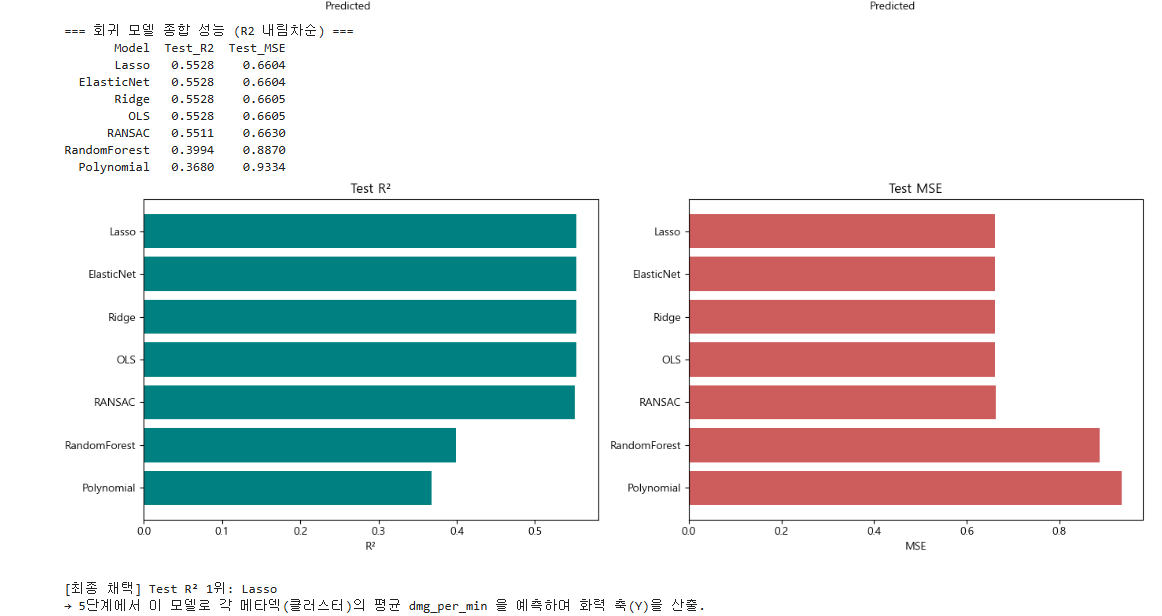
덱 구성(unit/trait) 76개만으로 dmg_per_min을 OLS 회귀한 결과 Test R² 0.553으로, 게임 상태 변수 없이도 화력의 절반 이상이 덱 구성으로 설명됐다. 당초 다중공선성을 우려했으나 OLS 최대 가중치(0.50)와 Ridge 최대 가중치(0.50)가 동일하고 Ridge·Lasso·ElasticNet의 R²가 모두 OLS와 같은 0.553이어서, 규제가 성능을 바꾸지 않음으로써 모델이 이미 안정적임을 역으로 입증했다(표본 18만 ≫ 피처 76). Lasso는 76개 중 1개만 0으로 만들어 희소성이 거의 없었는데, 이는 화력이 소수 사기 기물이 아니라 다수 캐리 기물의 고른 기여에서 나옴을 뜻한다. 화력 기여 상위는 Zilean·Jinx·Kayn 등 캐리 기물로 도메인 통념과 일치했다.

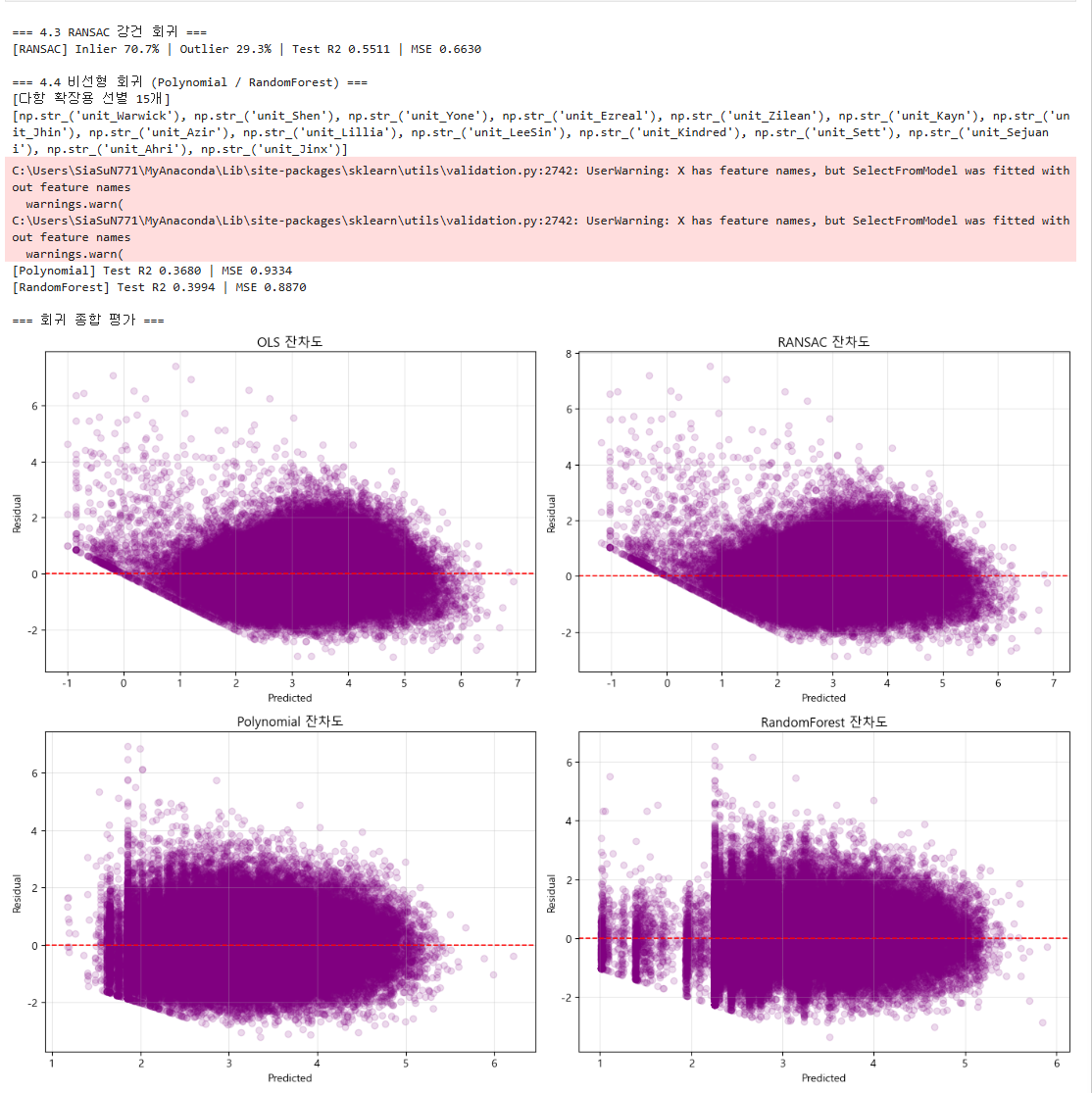
4.3~4.4 - 잔차도 4종 + 종합표
RANSAC으로 29.3%를 이상치로 배제했으나 R²(0.551)가 OLS와 거의 동일해, 해당 데이터가 제거 대상 노이즈가 아닌 정상 분포의 꼬리임을 확인했다. 비선형 모델이 더 우수하리라는 예상과 달리 Polynomial(0.368)과 RandomForest(0.399)가 선형(0.553)에 크게 못 미쳤는데, 이는 TFT 화력이 기물별 기여의 가산적 합 구조여서 선형 모델이 최적이며 다항은 15개 축소의 정보 손실까지 겹쳤기 때문이다. 잔차도상 선형 모델은 0 부근 음수 예측과 약한 이분산을 보였으나 전반적 무작위성은 양호했다. 최종 모델은 선형 계열 중 R² 1위인 Lasso(0.553)를 채택해 5단계 화력 축 산출에 사용한다. 특히 잔차도 좌측 하단으로 길게 뻗은 뚜렷한 사선 형태의 하한선은 타겟 변수인 분당 데미지가 0 미만이 될 수 없다는 게임 시스템의 절대적 물리 한계가 시각화된 결과다. 선형 모델은 이러한 데이터의 태생적 하한선을 인지하지 못하기 때문에 잔차가 예측값의 음수(e >= -y')를 뚫고 내려가지 못하는 기하학적 경계를 형성한 것이다.
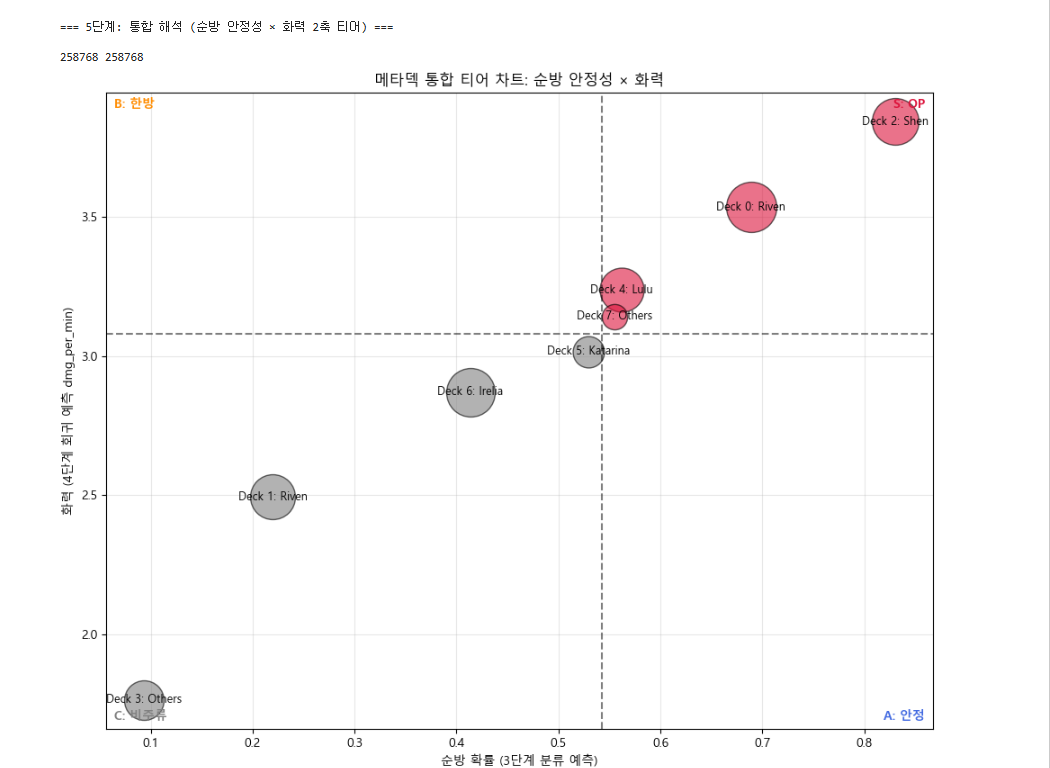
5.1~5.3 : 결과를 종합하여 X축(안정성)과 Y축(화력)으로 구성된 나만의 2축 사분면 티어표를 완성합니다.
- 2축 티어 차트와 통합 티어표
2단계가 분리한 8개 메타덱을, 3단계가 예측한 순방 확률(안정성 축)과 4단계가 예측한 화력(dmg_per_min 축)을 두 축으로 재배치해 통합 티어 차트를 완성했다. 8개 덱은 우상단 S티어(고승률·고화력) 4종과 좌하단 C티어(저승률·저화력) 4종으로 뚜렷이 양분됐으며, 두 축이 거의 대각선으로 정렬되어 화력이 높은 덱일수록 순방률도 높다는 점이 확인됐다 — 즉 화력만 높고 안정성이 낮은 '한방 덱'은 이 메타에 사실상 부재했다. 최상위는 Shen·Yone 기반 Deck 2(예측 순방률 0.831, 화력 3.84), 최하위는 비주류 조합의 Deck 3(0.093, 1.76)이었다. 한편 예측 순방확률을 실측 top4율과 대조하면 강한 덱은 과소평가, 약한 덱은 과대평가되는 평균 회귀 경향이 관찰됐는데, 이는 분류 모델이 극단적 성과를 보수적으로 추정함을 보여준다. 종합하면 클러스터링·분류·회귀 세 축이 하나의 티어 체계로 수렴하며, 비지도 학습이 찾은 덱 구조가 지도 학습의 성과 예측과 일관되게 맞물림을 실증했다.

5. 결론 및 향후 계획
5.1 결론
본 프로젝트는 TFT 시즌 4 챌린저 데이터를 대상으로 클러스터링·분류·회귀 세 가지 과제를 단일 파이프라인으로 통합해, "어떤 덱이 좋은 덱인가"라는 하나의 질문에 답하고자 했다. 비정형 문자열 데이터를 정형 특성 행렬로 변환하는 전처리에서 출발해, EDA에서 데이터 누수를 식별하고, 비지도 학습으로 8개 메타덱을 발굴한 뒤, 지도 학습으로 각 덱의 순방 안정성과 화력을 정량화하여, 최종적으로 2축 티어 차트로 종합했다. 그 결과 8개 메타덱이 고승률·고화력의 S티어와 저승률·저화력의 C티어로 뚜렷이 양분되며, 화력이 높은 덱일수록 순방률도 높다는 점을 실증했다.
본 프로젝트의 핵심 성과는 단일 모델의 성능 수치가 아니라, 분석 과정에서 마주친 문제를 논리적으로 진단하고 교정한 데 있다. 첫째, 데이터 누수를 조용히 제거하지 않고 "포함 시 정확도 0.91 → 제거 시 0.75"라는 대조를 통해, 기존의 고성능이 "덱이 강해서"가 아니라 "오래 살아남았다는 결과"에 기댄 거짓 성능이었음을 정량적으로 드러냈다. 둘째, 회귀 타깃을 placement에서 분당 데미지로 재정의함으로써 분류와 회귀가 서로 다른 질문에 답하도록 분리해, 세 과제가 하나의 티어 체계로 수렴하게 만들었다. 셋째, 교과서적 통념과 달리 부스팅이 배깅을 넘어서지 못했고 비선형 모델이 선형 회귀에 미치지 못한 결과를 정직하게 수용하여, TFT 화력이 기물 기여의 가산적 구조이며 다수결 기반 배깅이 게임의 무작위성에 강건하다는 도메인 해석을 도출했다. 요컨대 본 프로젝트는 머신러닝의 전 과정—전처리, 특성 공학, 차원 축소, 군집화, 분류, 회귀, 평가, 통합 해석—을 논리적 일관성을 유지하며 완주했으며, 결과가 가설과 어긋날 때 이를 분석의 소재로 전환하는 데 의의를 두었다.
5.2 한계
본 분석에는 몇 가지 한계가 존재한다. 첫째, 회귀 타깃인 분당 데미지는 생존 시간으로 정규화했음에도 순방 여부와의 상관이 완전히 제거되지 않아(약 0.71), 화력 축과 안정성 축이 완전히 독립적이지는 않다. 이로 인해 티어 차트에서 두 축이 대각선으로 정렬되어 "고화력·저순방의 한방 덱"이라는 사분면이 사실상 비게 되었다. 둘째, level을 정상 도메인 피처로 유지하기로 한 결정은 분석의 일관성을 위한 선택이었으나, level이 분류 특성 중요도에서 압도적 1위를 차지한 만큼 일부 사후정보적 성격이 잔존할 가능성을 배제할 수 없다. 셋째, 예측 순방 확률과 실측 top4율을 비교했을 때 강한 덱은 과소평가, 약한 덱은 과대평가되는 평균 회귀 경향이 관찰되어, 모델이 극단적 성과를 보수적으로 추정하는 한계를 보였다. 넷째, 본 분석은 10.25 단일 패치로 한정되어 메타 일관성은 확보했으나, 결과를 다른 패치나 시즌으로 일반화하기는 어렵다.
5.3 향후 계획
향후 연구는 다음과 같이 확장할 수 있다. 첫째, 화력과 안정성을 보다 독립적으로 분리하기 위해, 분당 데미지 대신 동일 라운드·동일 레벨 조건에서의 상대적 화력처럼 생존 길이의 영향을 더 엄격히 통제한 지표를 설계할 수 있다. 둘째, 여러 패치 데이터를 패치별로 분석한 뒤 메타덱의 티어 변화를 시계열로 추적하면, 특정 덱이 어떤 패치에서 부상하고 쇠퇴하는지를 포착하는 메타 변천사 분석으로 확장할 수 있다. 셋째, 본 프로젝트에서 게임 종료 시점 데이터로 사후 분석을 수행했다면, 향후에는 게임 중반(예: 4-1 라운드) 시점의 보드 상태만으로 최종 순방을 예측하는 실시간 추천 과제로 전환해, 누수 없는 순수 예측 모델로서의 실용성을 검증할 수 있다. 넷째, 본 분석이 수업 범위 내 기법으로 한정되었던 만큼, 향후에는 기물 간 동반 출현을 그래프로 모델링하는 등 덱 구성의 관계 구조 자체를 분석 대상으로 삼는 방향도 고려할 수 있다.